
AIに自社コンテンツを正しく理解させ、参照してもらうためには、人間向けのコンテンツだけでは不十分です。
AIが機械的に理解できる共通言語、すなわち「構造化データ」で、コンテンツの持つ本当の意味を伝える必要があります。
Google公式ドキュメントでも、「構造化データを追加することで、よりユーザーの興味をひく検索結果を表示できるようになり、ウェブサイトの利用も増えることが期待されます」と示されています。
構造化データとは、いわばAIに対する「コンテンツの公式な説明書」のようなものです。
整備することが、LLMO(大規模言語モデル)やAI検索エンジンから正しく評価され、引用されるための重要な第一歩となります。
この記事では、構造化データを用いてコンテンツの意味と構造をAIに正確に伝え、適切な情報抽出や引用に繋げるための具体的な方法について、わかりやすく解説していきます。
- 独自開発のLLMO分析ツールを活用
- 国内他社にはできない詳細なAI可視性(どれだけAIに言及・推奨・引用されているか)分析が可能
- 現状のLLMO対策の課題と、優先的に取り組むべき施策がまるわかり

現在、AI検索時代への対応やLLMO対策について、お考えでしたらぜひ弊社のLLMO無料診断をご活用ください。独自開発のLLMO分析ツールを活用し詳細な分析を実施。国内企業では現状不可能な高度なAI可視性分析が可能です。主要なAI(ChatGPT, Google Ai Overviews等)における競合比較や現状のLLMO対策の課題と、優先的に取り組むべき施策の可視化をいたします。ぜひ下記よりお気軽にお問い合わせください。
お問い合わせはこちらそもそも構造化データとは?LLMOでなぜ重要?
構造化データとは、Webページの内容をAI(検索エンジンなど)が正確に理解できるように、決められた形式(語彙)で意味づけをしたデータのことです。
人間はコンテンツを読むとき、文脈から意味を推測できます。一方でAIにとってはただの文字列にしか見えない場合があります。
構造化データを使って「これは商品名です」「これは価格です」「これはレビューの星の数です」と一つ一つにラベルを貼っていくことで、AIはコンテンツの「意味」をより正しく解釈できるようになるのです。
例えば、人間は「特製カレー」という文字を見れば、それが料理名だと文脈で理解できます。しかし、AIや検索エンジンにとっては、それが単なるテキストなのか、料理名なのか、本のタイトルなのか、すぐには判断できません。
そこで構造化データを使って、「これは料理名ですよ」「これは調理時間ですよ」と一つ一つに意味のラベルを付けてあげるのです。
構造化データには種類がある
構造化データには、ウェブサイトで扱う様々な情報に対応した「テンプレート(=タイプ)」が用意されています。
例えば、
- レシピのページなら
Recipeテンプレート - よくある質問のページなら
FAQPageテンプレート - 商品のページなら
Productテンプレート - イベント告知のページなら
Eventテンプレート
といった具合です。
かなり多くの種類があり、Googleがサポートする構造化データは以下のページにまとまっています。
様々な種類がある構造化データですが、そのうちLLMOに取り組むうえで優先度の高いものはいくつかあり、本記事後半の「LLMO対策で優先的に実装すべき構造化データ」にまとめました。
構造データの記述場所
構造化データは、Googleが推奨するJSON-LD形式の場合、以下のようにWebサイトのHTMLの<head>要素に、専用のフォーマットで記述します。※<body>要素に記載しても動作します。

記載した内容は人間が見るページには表示されず、検索エンジンがページ内容を読み取る際に使用されます。
なお、具体的な実装方法について詳しくは、記事後半の「構造化データの実装と検証方法」で解説しています。
続いては具体的に、LLMO対策で優先的に実装すべき構造化データを紹介します。
LLMO対策で優先的に実装すべき構造化データ
それでは、具体的にLLMO対策として特に実装の優先度が高い構造化データについて、それぞれの役割と書き方を解説します。
| カテゴリー | 種類 | 主な用途 | 主なプロパティ |
|---|---|---|---|
| 基本となる構造化データ | Organization | 企業や組織の基本情報を伝える | name, logo, url, sameAs, contactPoint |
| WebSite | サイト全体の情報とサイト内検索機能 | url, name, potentialAction | |
| BreadcrumbList | サイト内の階層構造を示す | itemListElement, ListItem, position, name, item | |
| コンテンツの種類に応じた構造化データ | Article | ブログ、ニュースなどの記事コンテンツ | headline, author, datePublished, dateModified, image |
| FAQPage | ページ内のよくある質問セクション | mainEntity, Question, acceptedAnswer, text | |
| Q&APage | 質問と回答が表示されるよくある質問ページ | mainEntity, Question, acceptedAnswer, suggestedAnswer, answerCount, upvoteCount | |
| HowTo | 手順や方法を解説するコンテンツ | step, tool, totalTime | |
| VideoObject | 動画コンテンツの情報 | name, description, thumbnailUrl, uploadDate, duration | |
| Product | 商品の情報(価格、在庫、レビューなど) | name, image, offers, aggregateRating, review | |
| 特定の業界・目的に特化した構造化データ | LocalBusiness | 店舗やオフィスの情報(住所、営業時間など) | name, address, telephone, openingHours |
| Event | イベントの情報(日時、場所など) | name, startDate, location, performer | |
| JobPosting | 求人情報 | title, baseSalary, jobLocation, employmentType |
それぞれ詳しく解説していきます。
①Organization / Person(組織・人物)
コンテンツの発信元である「組織」「人物」について、その実体をAIに伝えるのが Organizationスキーマ や Person スキーマです。
企業や団体など法人であればOrganizationスキーマ、個人が運営するサイトであればPerson スキーマを用います。
この構造化データは、Googleが重要視するE-E-A-T(経験・専門性・権威性・信頼性)をAIにアピールする上で非常に重要です。
誰がその情報を発信しているのかを明確にすることは、発信する情報の信頼性を高めることにつながります。
実際、大手SEO分析ツールを提供しているAhrefsも、「Organizationスキーマが単なる技術的な設定ではなく、Googleに対して自社の信頼性と権威性を証明し、ブランドのオンライン上での見え方をコントロールするための重要なSEO施策である」と解説しています。
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "企業名",
"url": "https://example.com/",
"logo": "https://example.com/logo.png",
"sameAs": [
"https://twitter.com/your-profile",
"https://www.facebook.com/your-profile"
]
}
</script>②WebSite(Webサイト)
Webサイト全体の情報を定義するWebSite構造化データは、LLM(大規模言語モデル)への最適化(LLMO)において重要です。
サイトの公式な「自己紹介」になるため
WebSite構造化データは、サイトの正式名称、代替名(略称など)、公式サイトのURLといった基本情報をAIに正確に伝えます。これにより、LLMは「このURLは、この名称の公式サイトである」と明確に紐付けて認識できます。
信頼性と権威性のシグナルとなるため
構造化データによって、サイト運営者(publisher)の情報を明示できます。これにより、LLMはそのサイトが信頼できる組織によって運営されていることを理解し、生成する回答の典拠として引用しやすくなります。
サイトの機能をAIに教えるため
特に重要なのが、サイト内検索機能(SearchAction)の存在をAIに伝えることです。これにより、Googleなどの検索エンジンが検索結果に「サイトリンク検索ボックス」を表示したり、AIが「〇〇(あなたのサイト)で△△を検索」といったアクションを理解したりする手助けになります。
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "WebSite",
"name": "株式会社Example",
"alternateName": "Example",
"url": "https://example.com/",
"potentialAction": {
"@type": "SearchAction",
"target": {
"@type": "EntryPoint",
"urlTemplate": "https://example.com/search?q={search_term_string}"
},
"query-input": "required name=search_term_string"
}
}
</script>③BreadcrumbList(パンくずリスト)
BreadcrumbListスキーマは、そのページがサイト全体のどの階層に位置するのかをAIに正確に伝えます。
これにより、AIは個々のページの文脈をサイト全体のテーマの中で理解しやすくなります。
また、構造化データの実装だけでなく、サイト構造じたいの最適化は、LLMOがサイトの専門性を評価する上でも重要です。しっかりと対応しておきましょう。
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [{
"@type": "ListItem",
"position": 1,
"name": "トップページ",
"item": "https://example.com/"
}, {
"@type": "ListItem",
"position": 2,
"name": "カテゴリー",
"item": "https://example.com/category/"
}, {
"@type": "ListItem",
"position": 3,
"name": "現在のページ",
"item": "https://example.com/category/page/"
}]
}
</script>④Article(記事)
Articleスキーマは、コンテンツの著者、公開日、更新日といった「情報の信頼性」に関わる基本情報をAIに正確に伝えます。
特に、情報の鮮度(Freshness)や権威性(Authority)が重視されるLLMOにおいて、誰がいつ発信した情報なのかを明示する Article スキーマは不可欠です。
実装コード例(JSON-LD)
JSON
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "記事のタイトル",
"author": {
"@type": "Person",
"name": "著者名"
},
"datePublished": "2023-10-26",
"dateModified": "2023-10-27"
}
</script>⑤FAQPage(よくある質問セクション)
FAQPageスキーマは、「質問と回答」のセットを明確にAIに提供します。
ユーザーが抱くであろう疑問に直接答えるこの形式は、AIが対話形式でアンサーを生成する際に、非常に引用しやすい情報となります。
ユーザーの検索意tuに合致したQ&Aをマークアップしておくことは、LLMO時代のSEOにおいて極めて有効です。
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "質問1の内容は?",
"acceptedAnswer": {
"@type": "Answer",
"text": "回答1のテキストが入ります。"
}
}, {
"@type": "Question",
"name": "質問2の内容は?",
"acceptedAnswer": {
"@type": "Answer",
"text": "回答2のテキストが入ります。"
}
}]
}
</script>⑥Q&APage(よくある質問ページ)
Q&Apage(よくある質問ページ)の構造化データは、質問と回答の組み合わせを検索エンジンに明確に伝えるため、LLMOに有効です。
なお、ひとつ前で紹介したFAQPageとの違いとして、Q&APageはページ全体が「よくある質問」のページの場合に使用します。
▼ページ全体が「よくある質問」のページの例
例:https://seo-writing-professionals.com/faq-article

実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "QAPage",
"mainEntity": [
{
"@type": "Question",
"name": "Q1. 注文方法を教えてください。",
"acceptedAnswer": {
"@type": "Answer",
"text": "A1. 当サイトの商品ページから直接ご注文いただけます。ご希望の商品をカートに追加し、決済画面へお進みください。"
}
},
{
"@type": "Question",
"name": "Q2. 送料はいくらですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "A2. 送料は全国一律500円です。ただし、5,000円以上のご購入で送料無料となります。"
}
},
{
"@type": "Question",
"name": "Q3. 返品は可能ですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "A3. 商品到着後7日以内であれば、未使用品に限り返品を承ります。詳細はお問い合わせください。"
}
}
]
}
</script>⑦HowTo(手順・方法)
HowToスキーマは、「〇〇のやり方」といった手順をステップ・バイ・ステップでAIに伝えます。
ユーザーが具体的な方法を知りたい場合、AIが手順を順序立てて説明する際の元情報となり、引用される可能性が高まります。
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "HowTo",
"name": "〇〇のやり方",
"step": [{
"@type": "HowToStep",
"text": "ステップ1の手順をここに記述します。"
}, {
"@type": "HowToStep",
"text": "ステップ2の手順をここに記述します。"
}, {
"@type": "HowToStep",
"text": "ステップ3の手順をここに記述します。"
}]
}
</script>⑧VideoObject(動画)
VideoObject(動画)の構造化データは、動画のタイトル、説明、サムネイルURL、アップロード日などの詳細情報をAIに伝えるため、LLMOで有効です。
LLMはこれらの情報を基に動画の内容を正確に理解し、回答で動画を表示します。
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "VideoObject",
"name": "【簡単レシピ】絶品カルボナーラの作り方",
"description": "初心者でも簡単に作れる、本格的なカルボナーラのレシピ動画です。材料も少なく、手軽に挑戦できます。",
"thumbnailUrl": "https://example.com/thumbnail.jpg",
"uploadDate": "2023-10-27T08:00:00+09:00",
"duration": "PT5M30S",
"contentUrl": "https://example.com/video.mp4",
"embedUrl": "https://example.com/embed/video",
"interactionStatistic": {
"@type": "InteractionCounter",
"interactionType": { "@type": "WatchAction" },
"userInteractionCount": 12345
}
}
</script>⑨Product(商品)
Product(商品)の構造化データは、商品名、価格、評価、在庫状況といった詳細を検索エンジンに提供するため、LLMOで有効です。
LLMはこれらの構造化された情報を活用し、ユーザーが商品を比較検討しやすくなるように、価格やレビューなどの情報をAIの回答で分かりやすく表示できます。
また、ChatGPTにはショッピング機能も追加されており、ユーザーの求める商品がカルーセル形式で販売ページへのリンクとともに表示されます。ChatGPT経由で買い物をするユーザーも増加が想定されるため、ショッピング機能で表示される可能性を高めるProduct(商品)の構造化データは重要だと言えるでしょう。
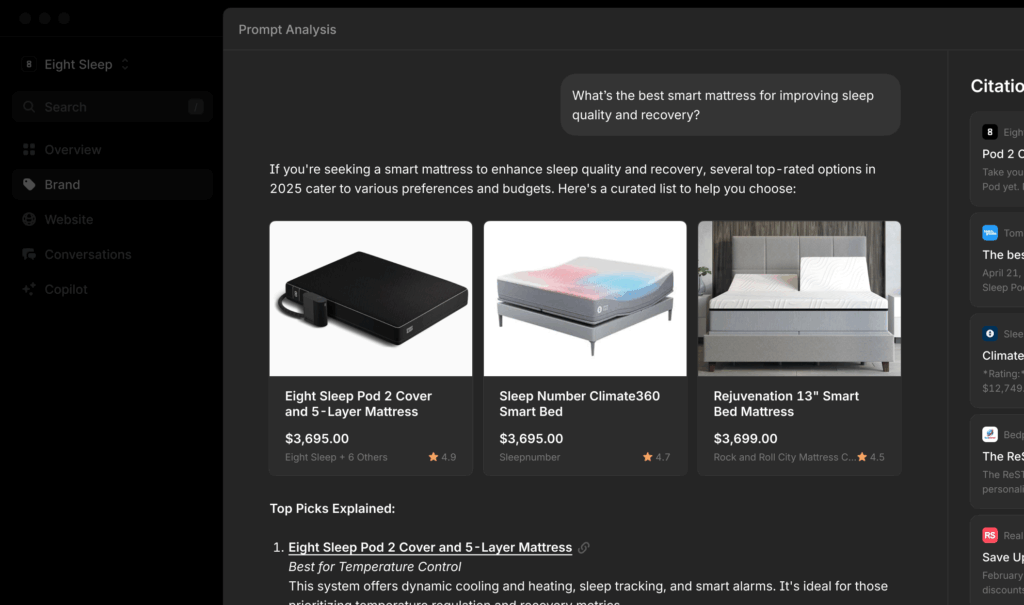
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "高機能ワイヤレスイヤホン XYZ-3000",
"image": [
"https://example.com/xyz-3000.jpg"
],
"description": "最新のノイズキャンセリング技術を搭載した、高音質なワイヤレスイヤホンです。長時間のバッテリー駆動も魅力です。",
"sku": "XYZ3000",
"brand": {
"@type": "Brand",
"name": "Example Electronics"
},
"review": {
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4.5",
"bestRating": "5"
},
"author": {
"@type": "Person",
"name": "田中 太郎"
}
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.4",
"reviewCount": "89"
},
"offers": {
"@type": "Offer",
"url": "https://example.com/product/xyz-3000",
"priceCurrency": "JPY",
"price": "15000",
"priceValidUntil": "2026-12-31",
"itemCondition": "https://schema.org/NewCondition",
"availability": "https://schema.org/InStock"
}
}
</script>⑩LocalBusiness(店舗やオフィスの情報)
LocalBusiness(店舗・オフィス)の構造化データは、店名、住所、電話番号、営業時間などのビジネス情報をLLMに正確に伝えます。
これにより、「近くのラーメン店」といった地域性が高い質問をしたユーザーに対し、自分たちのお店の情報が表示される可能性を高めることができます。
実装コード例(JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Restaurant",
"name": "Exampleカフェ",
"image": "https://example.com/photo.jpg",
"@id": "https://example.com/restaurant",
"url": "https://example.com/restaurant",
"telephone": "+81-3-1234-5678",
"priceRange": "¥¥",
"menu": "https://example.com/menu",
"servesCuisine": "カフェ",
"address": {
"@type": "PostalAddress",
"streetAddress": "丸の内1-2-3",
"addressLocality": "千代田区",
"addressRegion": "東京都",
"postalCode": "100-0005",
"addressCountry": "JP"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": 35.681236,
"longitude": 139.767125
},
"openingHoursSpecification": [
{
"@type": "OpeningHoursSpecification",
"dayOfWeek": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"opens": "11:30",
"closes": "22:00"
},
{
"@type": "OpeningHoursSpecification",
"dayOfWeek": "Saturday",
"opens": "11:30",
"closes": "23:00"
},
{
"@type": "OpeningHoursSpecification",
"dayOfWeek": "Sunday",
"opens": "11:30",
"closes": "21:00"
}
]
}
</script>⑪Event(イベント)
Event(イベント)構造化データは、コンサートやセミナーなどのイベント情報をAIや検索エンジンに正確に伝えるためのデータ形式です。「今週末のおすすめイベントは?」といったAIへの質問に対し、あなたのイベント情報が正確に抽出され、回答として引用(推薦)されやすくなります。
実装コード例 (JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Event",
"name": "東京テックカンファレンス 2026",
"startDate": "2026-03-15T09:00",
"endDate": "2026-03-16T17:00",
"location": {
"@type": "Place",
"name": "東京国際フォーラム",
"address": {
"@type": "PostalAddress",
"streetAddress": "丸の内3丁目5-1",
"addressLocality": "千代田区",
"addressRegion": "東京都",
"postalCode": "100-0005",
"addressCountry": "JP"
}
},
"description": "未来のテクノロジーについて議論するカンファレンスです。",
"offers": {
"@type": "Offer",
"price": "10000",
"priceCurrency": "JPY",
"url": "https://example.com/tickets"
}
}
</script>⑫JobPosting(求人情報)
JobPosting(求人情報)構造化データは、特定の職務に関する募集情報をAI(検索エンジン)に正確に伝えるためのデータ形式です。
「東京で働けるエンジニアの仕事は?」といったAIへの具体的な質問に対し、あなたの求人情報がAIによって直接抽出され、最適な候補として引用(推薦)されやすくなります。
また、AIが給与(baseSalary)や雇用形態(employmentType)、勤務地(jobLocation)を正確に理解するため、条件に合致した求職者に情報が届きやすくなります。
なお、主目的はGoogleの求人情報専用の検索結果(「Googleしごと検索」など)に表示されるようになり、求職者の目に触れる機会が劇的に増加させることであることを忘れないようにしましょう。
実装コード例 (JSON-LD)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "JobPosting",
"title": "ソフトウェアエンジニア (中途採用)",
"description": "<p>弊社の主力製品であるクラウドサービスの開発を担当していただきます。</p><p><b>主な職務内容:</b></p><ul><li>新機能の設計・開発</li><li>コードレビューとテスト</li></ul>",
"datePosted": "2025-10-20",
"validThrough": "2025-11-19T23:59:00+09:00", // 応募締切日
"employmentType": "FULL_TIME", // フルタイム
"hiringOrganization": {
"@type": "Organization",
"name": "株式会社サンプルテック",
"sameAs": "https://example.com"
},
"jobLocation": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"streetAddress": "サンプルビル 10F",
"addressLocality": "渋谷区",
"addressRegion": "東京都",
"postalCode": "150-0002",
"addressCountry": "JP"
}
},
"baseSalary": {
"@type": "MonetaryAmount",
"currency": "JPY",
"value": {
"@type": "QuantitativeValue",
"minValue": 6000000,
"maxValue": 9000000,
"unitText": "YEAR" // 年収
}
}
}
</script>構造化データの実装と検証方法
構造化データは、正しく実装して初めて効果を発揮します。
ここでは、推奨される実装方法と、実装後の検証手順を解説します。
実装方法はJSON-LDを推奨
構造化データの実装形式はいくつかありますが、Googleが推奨するJSON-LD形式をおすすめします。
JSON-LDは、HTMLの <body> や <head> タグ内に <script> タグとして記述するため、既存のHTML構造と分離して管理可能です。
これにより、実装や修正が容易になり、メンテナンス性が向上します。
実装の流れ
まず、実装したい構造化データのタイプを選択してください。
構造化データのタイプについては、前章「LLMO対策で優先的に実装すべき構造化データ」で解説した通りですので、自社サイトに必要だと考えるものを選定してください。
次に、選択したタイプに沿って、ページの情報を JSON-LD形式で記述します。
下記は <script type="application/ld+json"> タグ内に記述するJavaScriptのオブジェクト形式のコードです。
基本的な構造は以下のようになります。
{
"@context": "https://schema.org",
"@type": "選んだタイプ名",
"プロパティ名1": "値1",
"プロパティ名2": "値2",
"プロパティ名3": {
"@type": "別のタイプ名",
"内部プロパティ": "値"
}
}@context: 使用するスキーマを指定します。通常は"https://schema.org"です。@type: ステップ1で選んだタイプを指定します。(例:Article)- プロパティと値:タイプごとに定義されているプロパティ(
name、description、authorなど)に、具体的な情報を値として記述します。
▼記述例:簡単な記事ページ
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "JSON-LDの簡単な実装方法",
"author": {
"@type": "Person", 渡邉
渡邉実装コードの作成には、生成AIの活用が便利です。
最後に、作成したJSON-LDコードをWebページのHTMLに埋め込みます。
場所は <head> タグ内が推奨されていますが、<body> タグ内でも問題なく動作します。
HTMLを編集する技術がない(編集したくない)場合はプラグインやツールを活用
HTMLを直接編集しない方法は、WordPressかそうでない場合で大きく分けて2つあります。
CMSのプラグインを利用する(一番カンタン)
もしWebサイトを WordPress などのCMS(コンテンツ管理システム)で運営している場合、プラグインを利用するのが最も簡単で確実な方法です。
▼代表的なプラグイン
プラグインをインストールすると、記事の編集画面に「構造化データ(またはスキーマ)」の専用設定項目が追加されます。
例えば、「この記事はFAQです」と選んで質問と回答を入力したり、「レシピです」と選んで調理時間や材料を入力したりするだけで実装可能なので便利です。
フォームに沿って入力するだけで、プラグインが適切な構造化データを自動でHTMLの裏側に挿入してくれます。HTMLを1行も触る必要がありません。
構造化データジェネレーター + GTM (Googleタグマネージャー) を利用する
WordPressではないサイト(Wix, Squarespace, Jimdo, または静的HTMLサイトなど)で、HTMLの編集権限がない(または触りたくない)場合の方法です。
構造化データジェネレーターを開き、「イベント」「商品」「レビュー」などのタイプを選び、必要な情報をフォームに入力すると、JSON-LD形式のコードが自動で生成されます。
通常、(1) で作成したコードはHTMLの<head>タグ内などに貼り付ける必要がありますが、GTMを使えばHTMLを編集せずに挿入できます。
- GTMの管理画面で「カスタムHTML」タグを新規作成します。
- (1) で生成されたコードをそのまま貼り付けます。
- トリガー(配信ルール)を「対象のページビュー」に設定して公開します。
これで、GTMがあなたの代わりに、サイト訪問者に対して(そして検索エンジンに対しても)そのコードを配信してくれます。
「リッチリザルトテスト」を活用して正しく実装できているか検証
構造化データを実装した後は、必ずGoogleの公式ツール「リッチリザルトテスト」で検証しましょう。
ツールにページのURLかコードを直接入力することで、構造化データがGoogleに正しく認識されているか、エラーや警告がないかを即座に確認できます。
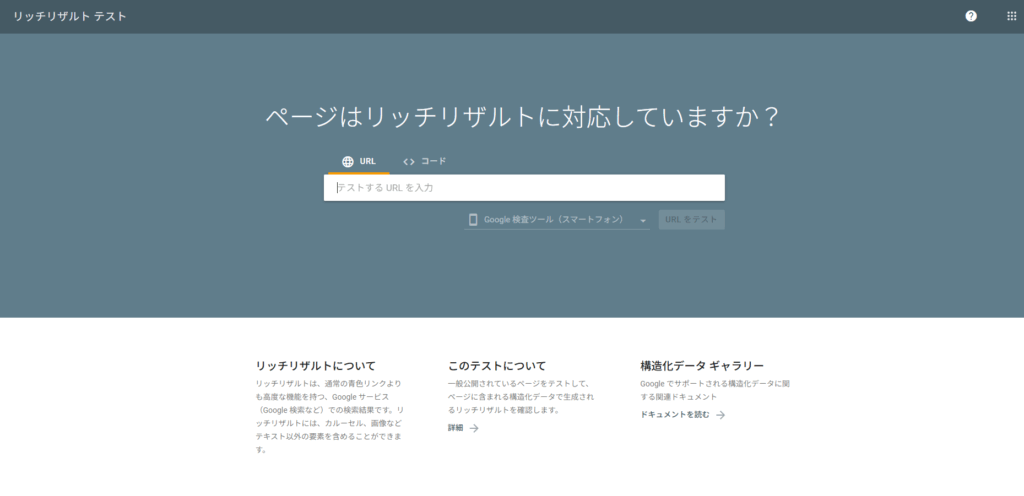
エラーが検出された場合は、修正しないとAIに正しく解釈されないため、修正をしてください。
LLMO対策ならシュワット株式会社
LLMO対策は今後企業のデジタルマーケティング活動において極めて重要な領域です。
しかし、専門的なノウハウが多く求められ、社内で推進していくのはなかなか難しいという企業も多いのではないでしょうか。
シュワット株式会社は、長年培ってきたSEOの知見に加え、LLMOの先進的なノウハウを備えています。
独自開発のLLMO分析ツールによるデータに基づく戦略設計、SEOとのハイブリッドな成果創出が可能です。
「LLMOの重要性は理解しているが何から手をつければいいか分からない」といったお悩みがあれば、ぜひ一度ご相談ください。
シュワット株式会社のLLMOコンサルティングサービスについて詳しくはこちら
まとめ
AI検索の比率が急増している中、コンテンツをAIに正しく理解させる「構造化データ」の重要性はますます高まっています。
今回ご紹介した構造化データの中から、自社のWebサイトにマッチしたものを正しく実装し、検証することで、AIからの評価を高め、既存コンテンツの価値を最大限に引き出すことができます。
この記事を参考に、ぜひ自社サイトへの実装を進めてみてください。
実装にあたり、お困りごとがある場合はぜひお気軽にお問い合わせください。
- 独自開発のLLMO分析ツールを活用
- 国内他社にはできない詳細なAI可視性(どれだけAIに言及・推奨・引用されているか)分析が可能
- 現状のLLMO対策の課題と、優先的に取り組むべき施策がまるわかり
現在、AI検索時代への対応やLLMO対策について、お考えでしたらぜひ弊社のLLMO無料診断をご活用ください。独自開発のLLMO分析ツールを活用し詳細な分析を実施。国内企業では現状不可能な高度なAI可視性分析が可能です。主要なAI(ChatGPT, Google Ai Overviews等)における競合比較や現状のLLMO対策の課題と、優先的に取り組むべき施策の可視化をいたします。ぜひ下記よりお気軽にお問い合わせください。
お問い合わせはこちら






