
ChatGPTやGoogleのAI Overviews、AIモードの登場により、ユーザーの情報収集行動は大きく変化しています。
この生成AI時代において、AI検索上での可視性向上を目指す「LLMO」は、デジタルマーケティングにおける新たな重要施策のひとつです。
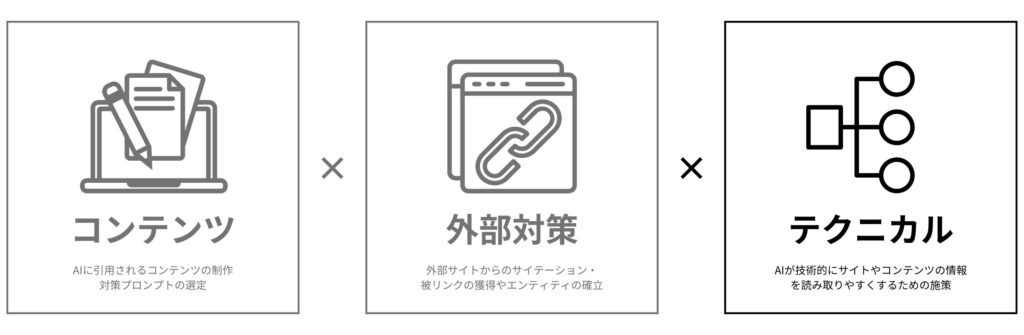
LLMOは、主に「コンテンツ」「テクニカル」「外部対策」の3つの施策から成り立ちます。
中でも、AIがサイトの情報を正確に収集・解釈できるよう、技術的な土台を整備する「テクニカルLLMO」は極めて重要です。
本記事では、LLMO強化に不可欠なテクニカル施策を紹介していきます。
具体的な実装方法からチェックリストまでをカバーしているので、ぜひお役立てください。
- 独自開発のLLMO分析ツールを活用
- 国内他社にはできない詳細なAI可視性(どれだけAIに言及・推奨・引用されているか)分析が可能
- 現状のLLMO対策の課題と、優先的に取り組むべき施策がまるわかり

現在、AI検索時代への対応やLLMO対策について、お考えでしたらぜひ弊社のLLMO無料診断をご活用ください。独自開発のLLMO分析ツールを活用し詳細な分析を実施。国内企業では現状不可能な高度なAI可視性分析が可能です。主要なAI(ChatGPT, Google Ai Overviews等)における競合比較や現状のLLMO対策の課題と、優先的に取り組むべき施策の可視化をいたします。ぜひ下記よりお気軽にお問い合わせください。
お問い合わせはこちらLLMOのテクニカル施策とは?
LLMOにおけるテクニカル施策とは、AIがあなたのサイトのコンテンツ引用やブランド推奨をしやすくするための、一連の技術的(テクニカル)な施策のことです。
AIは人間のように、ページを「感覚的」に読むのではなく、コードや構造から「機械的」に読み取ります。
テクニカル施策は、そのAIに対して「この情報は何なのか」「どこまで使って良いか」といった形で、ページ内容を読みやすく、使いやすいようにする技術です。
例えば、コンテンツがどんなに良くても、AIが技術的に読み取れなければ引用されることはありません。
「コンテンツ施策」や「外部対策」と並行して、総合的に取り組むことが、LLMO成功のポイントです。
それでは、具体的な施策を見ていきましょう。
LLMOに有効なテクニカル施策まとめ
LLMO強化に必要なテクニカル施策を、5つの領域に分けて紹介していきます。
まずは一覧表をご確認ください。
▼LLMO強化のテクニカル施策一覧表
| 領域 | 具体的な施策 |
|---|---|
| AIクローラー制御 | robots.txtによるクロール制御 |
| noindezによるクロール制御 | |
| XMLサイトマップによる重要ページの通知 | |
| llms.txtの設置※現状不要 | |
| robots制御はmax-image-preview:largeで画像引用 | |
| 構造化データ実装 | 各種構造化データの実装 |
| UX(ユーザーエクスペリエンス) | Core Web Vitalsの改善 |
| モバイルフレンドリー | |
| 煩わしい広告がない | |
| HTMLの最適化 | タイトル/ディスクリプションの最適化 |
| セマンティックHTML | |
| サイトの安全性と信頼感 | HTTPS(常時SSL化) |
| サイトアーキテクチャ | トピッククラスターモデルの形成 |
| 内部リンクの整備 | |
| パンくずリストの実装 | |
| 記事コンテンツ関連 | 著者情報の表示 |
| 最終更新日の表示 |
それぞれ詳しく見ていきましょう。
領域1:AIクローラー制御
AIクローラー制御とは、AIモデル(ChatGPTやGoogleのAIなど)の学習データ収集を目的とするクローラーによる、自サイトへのアクセスを管理・制限することです。
robots.txtによるクロール制御の明示
robots.txtは、サイトにアクセスするクローラーに対して、どのページをクロールして良いか、あるいはしてはいけないかを指示するためのファイルのことです。
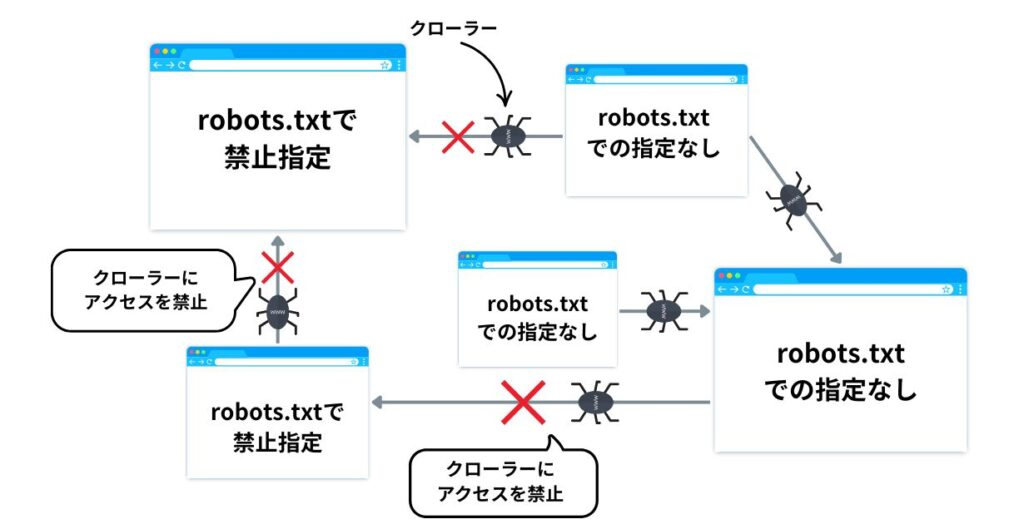
robots.txtのLLMOへの活用法について理解するためには、前提知識として、「クロールバジェット」について知っておく必要があります。
クロールバジェットとは、AIモデルの学習用クローラー(ChatGPT-Userなど)が、特定のサイトをクロールするために割り当てるリソース(時間やリクエスト数の上限)のことです。
クローラーは、インターネット上の膨大な情報を効率的に収集する必要があるため、1つのサイトのクロールに無限にリソースを割くことはできません。特に大規模なサイトや、更新頻度が低いと判断されたサイトでは、このバジェットが限られています。
AI検索で高い可視性を得るには、AIに質の高い重要なページ(例:専門記事、製品詳細)を効率よく学習してもらう必要があります。
しかし、サイト内にはAIの学習に不要なページ(例:管理画面、サイト内検索結果、パラメータ付きURL)も多く存在します。クローラーがこれらの「無駄なページ」にバジェットを消費してしまうと、本当に読んでほしい重要なページへのクロールが後回しになったり、頻度が下がったりします。
そこで、robots.txtを活用するのです。
実装方法
robots.txtに Disallow ルールを記述し、AIの学習に不要なページやディレクトリへのクロールを明示的にブロックします。
【記述例】
| User-agent: * 管理画面や検索結果など、学習に不要なページをブロック Disallow: /wp-admin/ Disallow: /search/ Disallow: /*?s= Disallow: /login/ |
XMLサイトマップによる重要ページの通知
XMLサイトマップ(sitemap.xml)は、サイト内に存在する重要なページのURLリストをクローラー(AIの学習ボット含む)に伝えるためのファイルです。
robots.txtが「クロールさせないページ」を指定する(防御的・除外)のに対し、sitemap.xmlは「クロールしてほしいページ」を積極的に教える(攻撃的・包含)役割を持ちます。
以下2つのポイントから、LLMOに有効です。
1. 「学習させたい重要ページ」の確実な発見
AIには、あなたのサイトの価値あるコンテンツ(専門記事、主要なサービスページ、詳細な製品情報など)を優先的に学習してほしいはずです。
XMLサイトマップにこれらのURLを記載することで、クローラーが内部リンクを辿るだけでは見つけにくいページや、新しく公開したページを素早く発見させることができます。
2. 更新情報の通知(鮮度の担保)
XMLサイトマップには、各ページの最終更新日時 (<lastmod>) を記載できます。
重要な情報(例:価格、仕様、最新の知見)を更新した際、この日付も更新してサイトマップを送信することで、AIクローラーに「情報が新しくなった」ことを伝え、再クロール(再学習)を促す効果が期待できます。
これにより、AIが古い情報ではなく、あなたのサイトの最新情報を回答に使いやすくなります。
実装方法
CMS(WordPressなど)のプラグインを使うか、自動生成ツールを利用することで簡単に実装できます。
XMLサイトマップについて詳しくは下記の記事をご覧ください。

llms.txtの設置※現状不要
llms.txtは、robots.txtの概念をさらに一歩進め、サイトのコンテンツをLLMの「学習(トレーニング)」に利用されることを制御もしくは拒否するために提案されている、新しいファイル形式です。

ただし結論、新技術でまだ標準化されていないため、今すぐの設置は不要との見解が中心です。
実際、2025年6月にはGoogle社のジョン・ミューラー氏が「llms.txtに対応するLLMベンダーはない」と述べています。(その後、2025年9月にも改めて不要だと唱えています。)
Google(Gemini)は上記の通りですが、一方ChatGPT側では、2025年10月ごろからllms.txtを読み取り始めています。
llms.txtの作成・設置の必要性は低いというのは間違いありませんが、リソースに余裕がある場合は設置をしてみてもいいといえるでしょう。
なお、技術者目線だとllms.txtは、技術的にAIとWebサイト間のコミュニケーションを円滑にする可能性を秘めているので、幅広いサイトで設置の方向性に動くと予測しています。
実装方法など、llms.txtについて詳しく知りたい方は、下記の記事をご覧ください。

robots制御はmax-image-preview:largeで画像引用
AIは、テキストの要約だけでなく、その内容を補足する関連性の高い画像を抽出し、回答に含めて表示することがよくあります。
meta name=”robots” タグを、max-image-preview:largeに設定することで、画像が引用される可能性が高まります。
理由は以下の通りです。
- AIに対し、あなたのサイトの画像を「高品質な大きなプレビュー」として回答に利用して良いという明確な許可を与えられるため。
- AIが、テキストだけの回答よりも魅力的で理解しやすい回答を生成しようとする際、許可された高品質な画像を優先的に引用するため。
ページの <head> タグ内に以下のように記述します。
記述方法
<meta name="robots" content="max-image-preview:large">領域2:構造化データの実装
「構造化データ」とは、ウェブページ上の情報(文字や数字)が「一体何なのか」を、検索エンジンやAIに正しく伝えるための“名札”をつける作業のことです。
例えば、「これは商品名です」「これは価格です」「これはレビューの星評価です」といった具体的な意味を、検索エンジンだけが読める専用の言葉(コード)で、ページの裏側にこっそり書き加えておくことを指します。
これを行うと、AIが内容を深く理解してくれるため、引用される可能性が高まります。
LLMOで実装が推奨される構造化データの種類
構造化データには様々な種類がありますが、LLMOで優先的に実装すべきものは下記の通りです。
| 構造化データの種類 | 主な目的と用途 | LLMへの効果 |
|---|---|---|
| Article | 記事のタイトル、著者、公開日、更新日、発行元などを明示する。 | 信頼性の基盤。 AIが「いつ、誰が、どの組織から発信された情報か」を正確に認識し、情報の鮮度や権威性を評価するのに役立ちます。 |
| FAQPage | 「よくある質問」とその「回答」のペアを明確にマークアップする。 | 直接的な引用のトリガー。 Q&A形式はAIが回答を生成する際に最も引用しやすい形式の一つです。ユーザーの具体的な疑問に対する回答として直接利用される可能性が高まります。 |
| Organization | 企業や組織の正式名称、ロゴ、住所、公式サイト、SNSアカウントなどを定義する。 | エンティティ(固有の存在)の確立。 AIに対して「この情報はこの企業が発信している」という事実を伝え、ブランドや組織の認知度・信頼性を高めます。 |
上記以外にもおすすめの構造化データがあり、詳しくは実装方法と合わせて下記の記事に記載していますので参考にしてください。

領域3:UX(ユーザーエクスペリエンス)
これは本来、人間のための指標ですが、LLMO(AI検索)においても、AIがサイトの品質を評価する上で非常に重要なシグナルとなります。
AIは「人間にとって有益で、信頼できる情報」を優先的に学習し、回答に利用しようとします。その際、「人間にとっての使いやすさ(UX)」を、サイトの品質や信頼性を測るための間接的な指標として利用すると考えられるからです。
例えば、以下のようなUXの問題は、LLMOに直接的な悪影響を与えます。
- 表示速度の遅延:ページの表示があまりに遅いと、AIクローラーが情報収集を非効率と判断し、クロールバジェット(巡回リソース)を使い切って途中で離脱する可能性があります。結果、重要な情報がAIに学習されず、回答に引用される機会を失います。
- Core Web Vitals (CWV) やモバイルフレンドリーの低評価:これらは「ページの使いやすさ」を測る指標であり、Google検索の直接的なランキング要因です。AIも同様に、これらの指標が低いページを「ユーザーが快適に使えない=品質が低い」と判断する可能性があります。
AIの回答に選ばれるためには、コンテンツ(中身)が良質であることはもちろん、その情報を届ける「器(うつわ)」であるWebページのUXも最適化されている必要があるのです。
それでは重要な要素をについてより具体的にみていきましょう。
Core Web Vitalsの改善
Core Web Vitals(コアウェブバイタル)の改善とは、Googleが重要視する3つのユーザー体験指標、LCP(読み込み速度)、INP(応答性)、CLS(視覚的安定性)の数値を最適化することです。
具体的には、画像の圧縮、不要なJavaScriptの削減、サーバー応答の高速化など、ページの表示や操作の快適性を高める技術的な修正を指します。
Core Web Vitalsは、Googleの直接的なランキング要因(ページエクスペリエンス)の一部でもあります。
施策例
| 指標 | 改善内容 | 具体的な施策例 |
|---|---|---|
| LCP (Largest Contentful Paint) | メインコンテンツの表示速度を高速化します。 | サーバーの応答時間の短縮、次世代フォーマット(WebP/AVIF)による画像圧縮 |
| INP (Interaction to Next Paint) | ユーザー操作への応答性を高めます。 | 不要なJavaScriptの実行を減らす、重い処理をバックグラウンドで実行する |
| CLS (Cumulative Layout Shift) | ページの視覚的な安定性を保ちます。 | 画像や広告にあらかじめサイズを指定し、読み込み途中でのレイアウトのズレを防ぐ |
弊社では、Core Web Vitals(表示速度)改善サービスも提供しているため、ぜひチェックしてみてください。
Core Web Vitals(表示速度)改善サービスはこちら
モバイルフレンドリー
多くのユーザーがスマートフォンからAI検索を利用することが想定されます。
AIがあなたのページを回答の引用元として提示した際、そのリンク先がモバイルで非常に見づらかったら、ユーザーはどう思うでしょうか? AI(とAIの提供元)の信頼が損なわれます。
そのため、AIは「モバイルで快適に読めること」を、引用するに値するページの前提条件として判断する可能性が非常に高いです。
また、Googleのクローラーは原則として「モバイルファーストインデックス」を採用しており、AIの学習用クローラー(Google-Extendedなど)も、スマホの画面幅でサイトを読み取っています。 モバイルでレイアウトが崩れていたり、文字が小さすぎたりすると、AIはコンテンツを正しく認識・学習することができません。
具体的な施策
| 施策 | 詳細 |
|---|---|
| レスポンシブデザインの採用 | PC、タブレット、スマホなど、どのデバイスの画面幅でもレイアウトが自動で最適化されるWebデザイン(レスポンシブ)を導入します。これが最も根本的かつ強力な施策です。 |
| タップターゲットの適切なサイズと間隔 | リンクやボタンが小さすぎたり、近すぎたりして押し間違えないよう、十分な大きさと間隔を確保します。 |
| フォントサイズの最適化 | モバイル端末でピンチアウト(拡大)しなくても読める、十分な文字サイズ(例: 16px目安)を確保します。 |
| ビューポート(表示領域)の設定 | HTMLの内に タグを正しく設定し、デバイスの幅に合わせてページが表示されるようにします。 |
煩わしい広告がない
AIが学習したいのは、あなたのサイトが提供する独自の価値(記事本文、製品解説など)です。
しかし、ページを開いた瞬間に画面全体を覆う広告(インタースティシャル広告)や、本文を読み進めると割り込んでくる広告、画面の大部分を占める追従バナーなどは、AIクローラーが本文を読み取る際の物理的な障害となります。
また、過度な広告は「ユーザー体験を著しく損ねるページ」であり、AIは「品質が低い」「信頼性が低い」「スパム的である」という強力なシグナルとして受け取ります。AIは、自身の回答の信頼性を担保するために、そうした低品質なページを学習対象から除外したり、引用を避けたりするようになります。
具体的な施策
| 施策 | 詳細 |
|---|---|
| インタースティシャル広告の廃止 | ページ表示時やページ遷移時に、画面全体を覆ってコンテンツを隠すタイプの広告(特に、すぐに閉じられないもの)は避けます。 |
| 広告の配置と分量の見直し | コンテンツ(本文)よりも広告が目立つような配置にしない。画面の大部分(特に上部)を占める「スティッキー広告(追従広告)」は使用しない。 |
| レイアウト シフト(CLS)の防止 | 広告が後から読み込まれることで本文のレイアウトが「ガクッ」とずれる現象(CLS)は、UXを大きく損ねます。広告スロット(掲載枠)のサイズをあらかじめCSSで確保しておくなど、レイアウトがずれないようにします。 |
| 誤解を招く広告の排除 | コンテンツ(記事)やナビゲーションボタンと見間違うようなデザインの広告は、ユーザーを騙す行為(Deceptive patterns)とみなされるため、明確に「広告」とわかるようにします。 |
領域4:HTMLの最適化
AI (LLM) は、人間のようにWebページを「見て」理解しているわけではありません。
HTMLコードの構造や、そこに記述された「タグ」を手がかりにして、そのページに何が書かれているか、どこが重要かを判断しています。
メタデータやHTMLタグを最適化することは、AIに対して「このページの主題はこれで、構造はこのようになっており、この部分は特に重要です」と、AIが理解できる言語で明確に伝える行為です。
これを怠ると、AIはあなたのコンテンツの価値や文脈を正しく解釈できず、結果としてAI検索の回答で引用・参照されにくくなります。
タイトル/ディスクリプションの最適化
titleとdescriptionを最適化しましょう。
titleタグ (<title>)
titleタグは、そのページの「主題」をAIに伝える、最も強力なシグナルです。AIが「このページは何についてのページか?」を判断する際に用いられます。
ページの核心的なキーワードを含め、内容を正確に(かつ簡潔に)記述してください。また、AIが文脈を理解しやすいよう、単なるキーワードの羅列ではなく、自然な文章(またはそれに近い形)にしましょう。
meta descriptionタグ(<meta name="description">)
meta descriptionタグは、そのページの「要約」を伝えるタグです。AIが直接的に学習するかはモデルによりますが、クローラーがページ内容の概要を把握し、文脈を理解するのを助けます。AI検索の回答スニペット(引用の補足)として利用される可能性もあります。
実際、以下のChris Long氏によるXの投稿にもある通り、ChatGPTのソースコードから、ディスクリプションが読み取りに重点的に用いられていることがわかります。
ページの内容を正確に要約した、魅力的な文章を記述しましょう。(例:120文字程度)titleタグ同様、ユーザー(とAI)が読んだときに内容を理解できる文章にしてください。
セマンティックHTML
セマンティックHTMLとは、<div>や<span>のような「見た目のため」だけのタグではなく、<article>(記事)や<nav>(ナビゲーション)のように、タグ自体が「意味」や「役割」を持つHTMLのことです。
見出しタグ(<h1>など)もセマンティックHTMLの重要な一部ですが、ここではページ全体の「構造」に関わるタグに焦点を当てます。
AI(LLM)は「見た目」ではなく「構造」で判断する
AIは人間のように「ここの大きなブロックが本文で、右側の細いカラムがサイドバーだな」と視覚的に判断しているわけではありません。 AIはHTMLのコード(骨格)を読み、どのタグで囲まれているかによって、そのコンテンツの「役割」を理解します。
もしサイト全体が<div>タグだらけで作られていたら、AIはどれが本文で、どれがヘッダー、どれが広告なのかを正確に区別できません。
セマンティックHTMLを正しく使うことは、AIに対して「ここからここまでが“主要な本文”です」「こっちは“補足情報”です」「ここは“ナビゲーション”なので学習対象から除外してよいです」と、ページの設計図を正確に教えられます。
これにより、AIはあなたのサイトの最も価値ある部分(=本文)をピンポイントで効率よく学習できるようになり、AI検索の回答における引用の精度が向上します。
(NG例)<div>だらけの構造
<div class="header">...</div>
<div class="main-content">
<div class="article-title">...</div>
<div class="article-body">...</div>
</div>
<div class="sidebar">...</div>(これではAIは class 名から推測するしかなく、不確実です)
(OK例)セマンティックな構造
<header>...</header>
<main>
<article>
<h1>...</h1>
<p>...</p>
</article>
</main>
<aside>...</aside>
<footer>...</footer>特に、見出しタグ(<h1>, <h2>, <h3>…)は重要です。<h1>が「大見出し(主題)」、<h2>が「章」、<h3>が「節」といった具合に、AIは見出しタグを頼りに「どこからどこまでが、どのトピックについて書かれているか」を把握します。
以下のポイントをおさえておきましょう。
<h1>はページに1つだけ使用し、そのページの主題(titleと連動)を記述します。<h2>,<h3>を使い、記事の論理的な構造(階層)に合わせて正しくマークアップします。
(デザイン(文字の大きさ)のためだけに見出しタグを使わない)- 見出しを見ただけで、そのセクションの内容が推測できるような、具体的で分かりやすいテキストにします。
領域5:サイトの安全性と信頼感
LLMO(AI検索)において、サイトの安全性と信頼感は「コンテンツの中身以前の土台」として非常に重要です。
AI(LLM)は、ユーザーに提供する回答の「信頼性」を担保することを最重要課題の一つとしています。もしAIが危険なサイトや、信頼できない情報源(詐欺サイト、フィッシングサイトなど)を引用・参照してしまえば、AI自体の信頼が失墜するからです。
そのため、AIは学習・引用するサイトが「安全であるか」「信頼できるか」を、人間のユーザー以上に厳しく評価します。
技術的に安全性を証明するうえでは、https化(常時SSL化)が重要です。
https化(常時SSL化)の重要性
https://(常時SSL化)とは、サイトとユーザー間の通信を暗号化し、第三者による盗聴やデータの改ざんを防ぐ仕組みです。
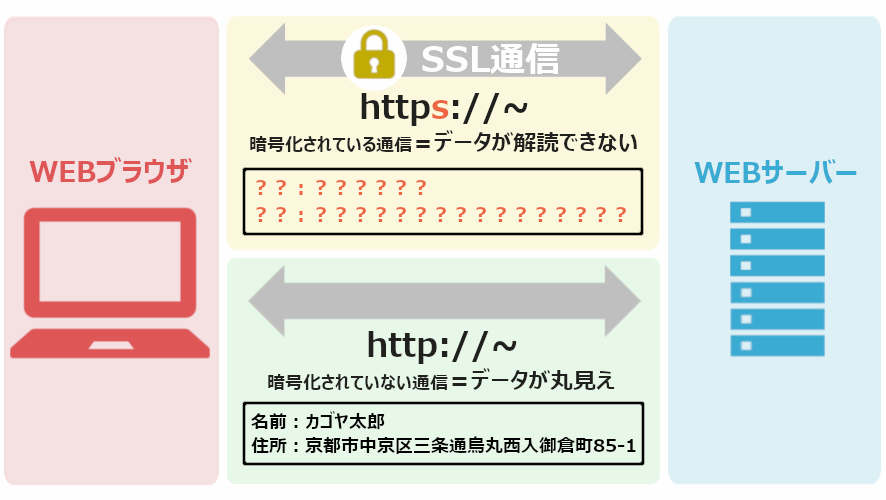
現在、https://化はWebサイトの「標準装備」です。いまだにhttp://(暗号化されていない)状態のサイトは、ブラウザから「安全ではありません」と警告されます。
AIも同様に、これを「セキュリティ意識が低い、管理されていない、信頼できないサイト」と判断する強力なシグナルとします。
したがって、https化は、「推奨」ではなく「必須」の施策です。もしサイトがhttp://のままなら、最優先で「常時SSL化」対応(サーバーでの設定、httpsへのリダイレクト)を行ってください。
参考:NTTドコモビジネス「常時SSLでセキュリティ対策を」
領域6:サイトアーキテクチャ
サイトアーキテクチャ(サイトの構造設計)の最適化は、LLMO(AI検索)において非常に重要です。
AIは、個々のページの品質を見るだけでなく、サイト全体として「どのようなトピックについて」「どれだけ深く、体系的に」情報を網羅しているかを評価します。
優れたサイトアーキテクチャは、AIに対してその「専門性」と「情報の関連性」を効率よく伝えるための“設計図”として機能します。
トピッククラスターモデルの形成
トピッククラスターモデルを形成することで、サイトの「専門性」をAIに証明することができます。
Webサイト内のコンテンツを特定のテーマ(トピック)ごとにグループ化し、それらのコンテンツ同士を内部リンクで結びつけることで、検索エンジンからの評価を高めるための戦略です。
トピッククラスターでは、1つの広範なテーマ(例:「ダイエットとは」)を扱う「ピラーページ(柱)」と、そのテーマに関連する具体的な小テーマ(例:「ダイエット サプリ」「ダイエット 運動」「ダイエット 食事制限」「ダイエット つらい」)を扱う複数の「クラスターページ(詳細)」を作成します。
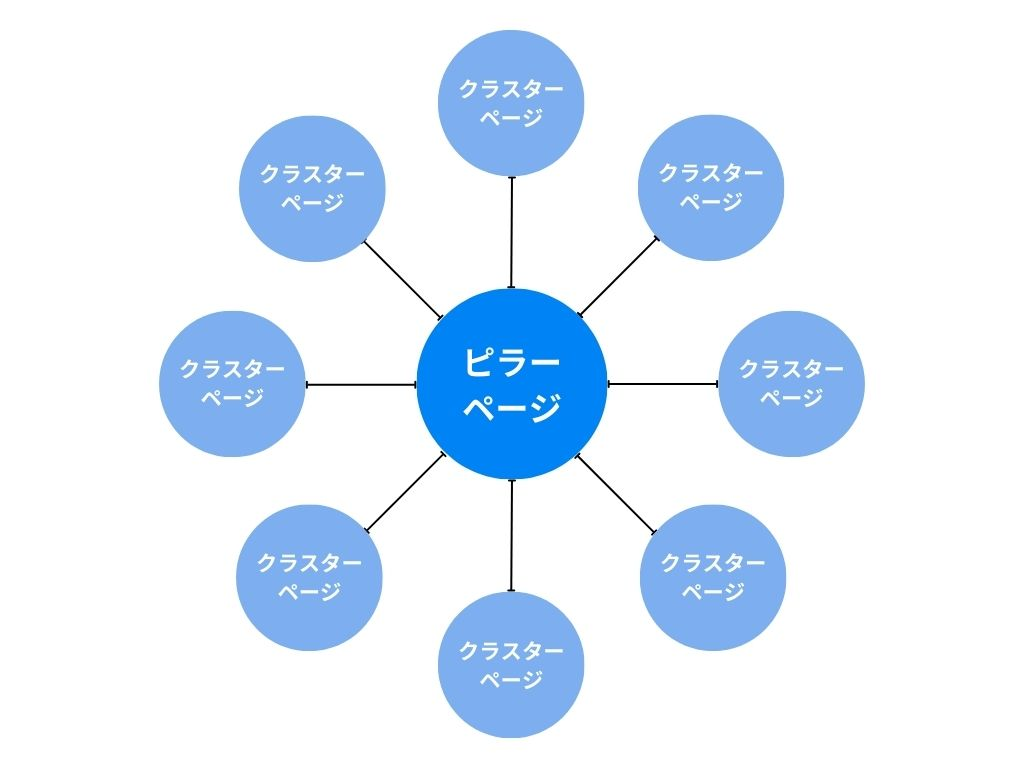
そのうえで、それぞれを内部リンクで相互にリンクさせます。
AIは、このように体系化された情報群(クラスター)を発見すると、「このサイトは“ダイエット”というトピックについて、広く、かつ深く理解している専門家(情報源)だ」と認識します。
AIが複雑な質問に答える際、断片的な情報源よりも、このように網羅的・体系的に整理された情報源を優先的に参照するため、引用やブランドメンションの可能性が高まるのです。
なお、トピッククラスターモデルについて詳しくは下記の記事をご参照ください。

内部リンクの整備
内部リンクは、AIクローラーがサイト内を巡回するための「道しるべ」であり、ページ間の「関連性」を伝える最も重要な手がかりです。
AIは内部リンクを辿ることで、「どのページが重要なのか(多くのリンクが集まるページ=重要)」や、「どのページとどのページが文脈的に関連しているか」を学習します。
トピッククラスターモデルも、この内部リンクによる関連付けがなければ機能しません。
具体的な施策
| 施策 | 詳細 |
|---|---|
| クラスターからピラーへ | すべてのクラスターページから、中心となるピラーページへリンクを張ります。 |
| ピラーからクラスターへ | ピラーページから、関連するクラスターページ群へリンクを張ります。 |
| 関連ページ同士のリンク | 文脈上関連性の高いページ同士を「関連記事」として適切にリンクします。 |
| アンカーテキストの最適化 | リンクの文字列(アンカーテキスト)は、「こちら」ではなく「LLMOのsitemap.xml活用法」のように、リンク先のページ内容がAIに伝わる具体的なキーワードを使います。 |
なお、内部リンク最適化のポイントについて詳しくは下記の記事をご覧ください。

パンくずリストの実装
パンくずリスト(例: ホーム > ブログ > LLMO > サイトアーキテクチャ)は、AIに対して、そのページがサイト全体の「どの階層(カテゴリ)に属しているか」を明確に伝えるシグナルです。
AIがページを学習する際、そのページ単体で見るのではなく、「この記事は“LLMO”というカテゴリに属する情報なのだな」と文脈(カテゴリ構造)の中で正しく位置づけることができます。
| 施策 | 詳細 |
|---|---|
| 主要なページすべてに設置 | すべての主要なページ(特に階層が深くなるページ)に、パンくずリストを設置します。 |
| 構造化データマークアップ | BreadcrumbListという構造化データを用いて、パンくずリストの階層関係をAIにより正確に(機械判読可能な形で)マークアップします。 |
領域7:記事コンテンツ領域
LLMOの記事コンテンツ領域とは、AI検索(SGE)の回答に引用・参照されるためのコンテンツ最適化です。AIは信頼できる最新情報を重視するため、専門性を示す「著者情報」と、情報の鮮度を示す「最終更新日」の明記は極めて重要です。
これらはGoogleのE-E-A-T(信頼性)評価に直結し、AIが回答ソースとしてコンテンツを選ぶ確率を高めるために不可欠な要素です。
著者情報の表示
LLMOによる記事生成が広がる中、SEOにおいて「著者情報」の重要性が増しています。GoogleはE-E-A-T(経験・専門性・権威性・信頼性)を重視しており、AI単体ではこれらを証明するのが困難だからです。特に実体験に基づく「経験」はAIにはありません。
そこで、AIが生成したコンテンツを人間の専門家が監修・編集し、その著者(監修者)情報を明記することが不可欠です。これにより、記事の品質と信頼性を人間が担保していると示せ、Googleと読者の双方からの評価を高めることができます。著者情報の明示は、AI時代のコンテンツの「信頼の証」となります。
最終更新日の表示
「最終更新日」の表示は極めて重要です。
Googleは、ユーザーに価値ある情報を提供するため、コンテンツの「鮮度(Freshness)」を評価基準の一つとしているからです。
特に情報が頻繁に変わる分野(技術、ニュース、法律など)では、古い情報は読者のニーズを満たせません。
記事が現在も正確で信頼できる情報であることをAIに示し、可視性を高めるための重要な施策となります。
LLMOのテクニカル施策チェックリスト
本記事で解説した施策をチェックリストとしてまとめました。
自社サイトの現状把握にご活用ください。

LLMO対策ならマーケティングAIX by シュワット株式会社
LLMOの重要性が増す一方で、「何から手をつければ良いか分からない」「テクニカルな実装は社内リソースでは難しい」といった課題をお持ちの企業様も少なくありません。
シュワット株式会社では、コンテンツ制作や外部対策、テクニカル施策の実装まで、LLMO対策をワンストップでご支援するプランを提供しております。
貴社のサイトの現状を専門家が分析する「LLMO無料診断サービス」も行っており、本記事で解説したようなテクニカルな課題点を洗い出し、具体的な改善策をご提案します。
AI時代に対応したサイト基盤の構築に関心をお持ちでしたら、ぜひ一度ご相談ください。
LLMOコンサルティング・LLMO対策支援サービスについて詳しくはこちら
まとめ
LLMOにおけるテクニカル施策は、AIの理解を促進し、自社コンテンツの価値を正しく伝達するための不可欠な基盤です。
今回説明した施策は一度実装して終わりではなく、AI技術の進化や検索エンジンの仕様変更に合わせて継続的に見直しと改善を行っていくことが、これからのデジタルマーケティングにおいて重要な成功要因となります。
マーケティングAIXを提供するシュワット株式会社では、従来のSEOに加えてAIに引用・参照されるためのLLMO対策にも対応しています。
さまざまなサイトを支援してきた実績から、サイトごとに最適な対策プランを提案させていただきますので、ぜひお気軽にご相談ください。
- 独自開発のLLMO分析ツールを活用
- 国内他社にはできない詳細なAI可視性(どれだけAIに言及・推奨・引用されているか)分析が可能
- 現状のLLMO対策の課題と、優先的に取り組むべき施策がまるわかり
現在、AI検索時代への対応やLLMO対策について、お考えでしたらぜひ弊社のLLMO無料診断をご活用ください。独自開発のLLMO分析ツールを活用し詳細な分析を実施。国内企業では現状不可能な高度なAI可視性分析が可能です。主要なAI(ChatGPT, Google Ai Overviews等)における競合比較や現状のLLMO対策の課題と、優先的に取り組むべき施策の可視化をいたします。ぜひ下記よりお気軽にお問い合わせください。
お問い合わせはこちら





