



SEOやWebサイトの運用を進めるうえで、絶対に欠かせない知識のひとつである「robots.txt」。
robots.txtは、検索エンジンがWebサイトを巡回し、情報を収集するクローラー(ロボットのようなもの)の動きをコントロールするために作成するテキストファイル(.txt)です。
主に、サイトへの過負荷を防ぎ、特定のページをクローラーに巡回させないようにするために使用されます。
ここで、「それってそんなに重要なの?」と感じた方も多いのではないでしょうか?
実は、robots.txtはSEO対策を進めるうえで非常に重要で、適切に設定することでWebサイト全体のSEO評価を高めることが期待できます。
この記事では、robots.txtについての基礎知識から、SEO効果、適切な設定方法、注意点について詳しく解説していきます。
Webサイトの運用やSEOに取り組む方にとって、必須の知識なので、ぜひ記事を最後まで読んで理解を深めてくださいね。
- 狙ったキーワードで検索上位がとれていない
- 戦略的にSEO対策をしたい
- 検索順位改善だけでなく売上・利益にもつなげたい

現在、上記のようなお困りごとがありましたら、SEOコンサルティングで圧倒的な成果を創出してきた我々『シュワット株式会社』へご相談ください。SEO対策にとどまらず売上・利益などビジネス的な成果を追求し、戦略設計から施策の実行、インハウス化支援まで、ニーズに合わせた最適なプランで強力にサポートいたします。
robots.txtとは?
robots.txtとは、サイトを巡回するクローラーの動きをコントロールするために作成するテキストファイル(.txt)のことです。
前提知識として、Googleなどの検索エンジンは、「クローラー」という様々なWebサイトを巡回するロボットがページ内容を読み取り、その後にその内容をデータベース上にインデックス(登録)しています。
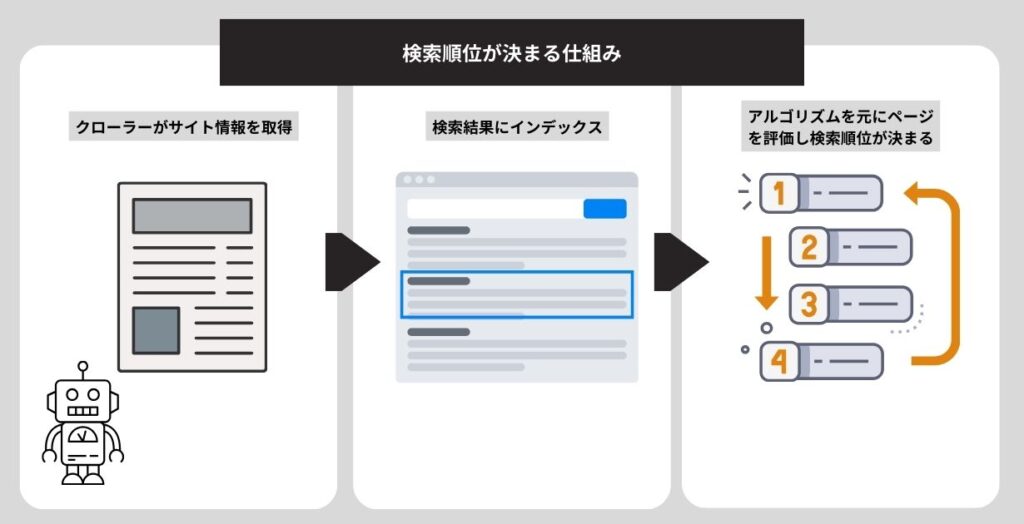
robots.txtは、この検索エンジンのクローラーに対して、サイトのどのURLにアクセスして良いか、どのURLにアクセスしてはいけないか、を伝えることができます。
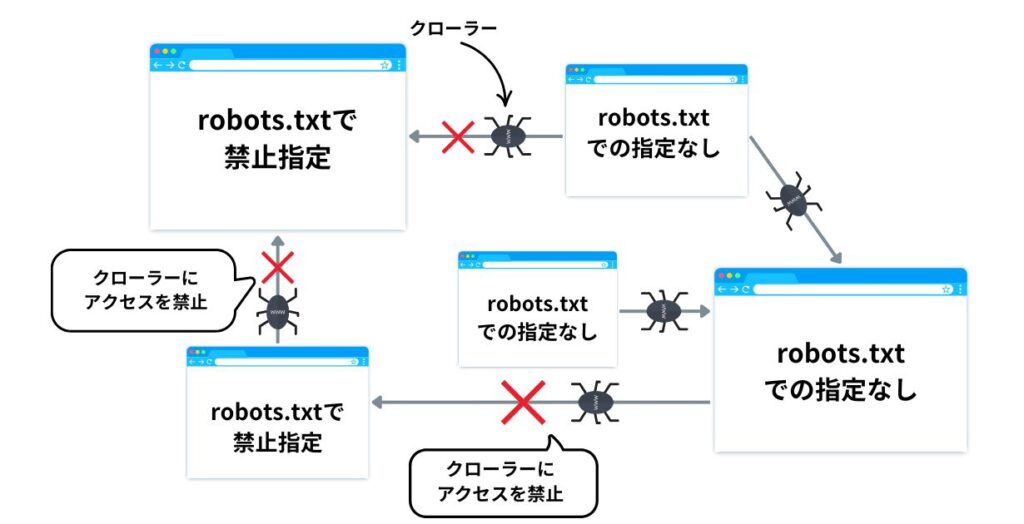
robots.txtファイルの使用目的
robots.txtファイルは主に、検索エンジンのクローラーによるサイトへのアクセスを最適化する目的で使用されます。
まず前提として、サイトごとにクローラーが巡回できる量は決まっており、ページ数が多いとクロールされないページが出てきてしまうことがあります。
しかし、検索エンジンに表示させたい重要なページがクロールされないのは避けたいところですよね。
そこで、「robots.txtファイルの出番」です。
robots.txtファイルでクローラーの巡回が不要なページへのアクセスを制限することにより、クロール量に余裕が生まれ、ウェブサイト内の重要なページが優先してクロールされるようになります。
その結果、重要ページが検索エンジンに知ってもらえ、検索結果に表示される可能性が高まるのです。
その他にも、ファイル形式別で以下のような目的で使用されます。
| ファイル形式 | 使用目的 | 注意点 |
|---|---|---|
| ウェブページ | サーバー過負荷回避、重要でない/類似ページのクロール防止。 | 検索結果に表示されないようにする目的では使用しないこと。 |
| メディアファイル | 画像、動画、音声ファイルなどが検索結果に表示されないように管理。 | 他のページからのリンクやユーザーによる直接アクセスは引き続き可能です。 |
| リソースファイル | 重要でない画像、スクリプト、スタイルファイルなどのブロック。 | ページ分析に不可欠なリソースをブロックすると、Googleがページを適切に把握できなくなる可能性があります。 |
 渡邉
渡邉特にページ数の多い大規模サイトでは、重要なページへのクロールリソースを確保するために、重要でないページや類似ページのクロールを防ぐために、積極的にrobots.txtが使用されます。
注意点:robots.txtを設定しても検索結果に表示されなくなるわけではない
robots.txtは。あくまでクローラーへの「指示」であり、ページを検索結果から完全に非表示にするためのものではない点に注意が必要です。
すでに検索結果に表示(インデックス)されているページを、後からrobots.txtでクロール制限の対象とした場合、クローラーのアクセス自体はなくなりますが、インデックスがなくなるわけではないので、そのページは引き続き検索結果に表示され続けるのです。
したがって、ページを検索結果から完全に非表示にしたい場合は、別の命令文である「noindex」を使用する必要があります。
「nonidex」に関しては、下記で詳しく解説しています。

robots.txtファイルの設置手順
robots.txtファイルの書き方を以下の6つの手順に分けて解説します。
- robots.txt ファイルの作成
- robots.txtファイルの設置
- robots.txt のルールの記述
- robots.txt ファイルのアップロード
- robots.txt のマークアップのテスト
- robots.txt ファイルのGoogle への送信
それでは各ステップごとに詳しく見ていきましょう。
1. robots.txt ファイルの作成
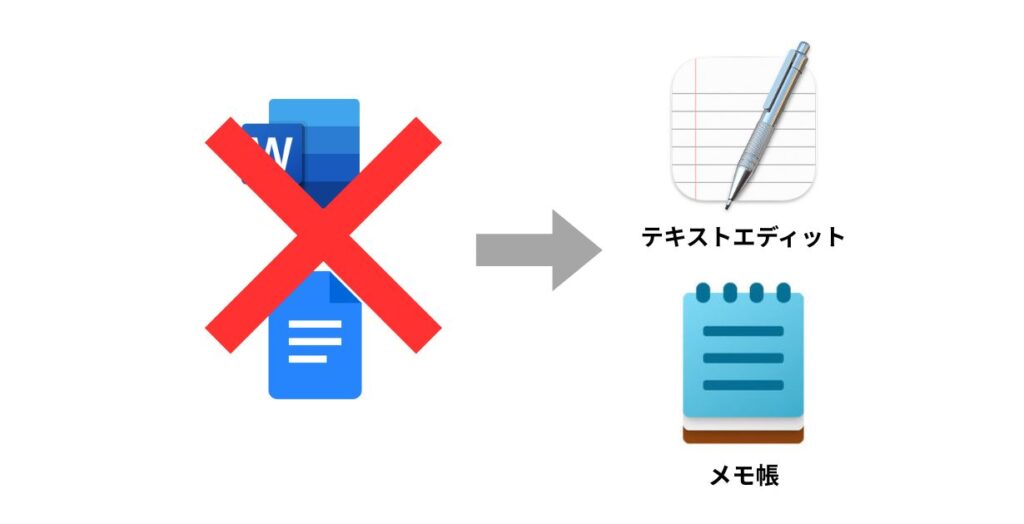
robots.txtファイルを作成するには、まずファイル名を「robots.txt」とし、テキスト形式で作成する必要があります。
WordやGoogleドキュメントではなく、「メモ帳」や「テキストエディット」のような純粋なテキストエディタを使用しましょう。
これは、WordやGoogleドキュメントが独自の形式で保存し、クローラーが認識できない文字を含める可能性があるためです。
作成したrobots.txtファイルは、サイトのルートディレクトリに配置する必要があります。
例えば、https://www.example.com/ のサイトであれば、ファイルはhttps://www.example.com/robots.txt に置きます。
作成にあたり、以下のようなポイントも抑えておきましょう。
- ファイル形式はUTF-8エンコードを指定してください。
※GoogleはUTF-8以外の文字を無視する場合があります。 - rots.txtファイルは、配置されたプロトコル、ホスト、ポート内のパスにのみ適用されます。例えば、https://example.com/robots.txt は https://example.com/ 内にのみ有効で、http://example.com/ や https://m.example.com/ といった異なるプロトコルやサブドメインには適用されません。
- 一つのサイトに配置できるrobots.txtファイルは一つだけです。
- サブディレクトリに配置しても効果はありません。
2. robots.txt の記述方法とサンプルコード
robots.txt は、以下の4つの「グループ」で構成されています。
4種のグループ
- User-agent:ルールを適用するクローラーを指定する。(GoogleやYahoo!など)
- Disallow:クロールを禁止するディレクトリやページを指定する。サイト全体も指定可能。
- Allow:Disallow で禁止されたうち、特別にクロールを許可するディレクトリやページを指定する。
- Sitemap:サイトマップのURLを検索エンジンに伝える。
robots.txtのサンプルコードとしては、以下のようになります。
User-agent: *
Disallow: /example/
Allow: /example/0001
Sitemap:https://example.com/sitemap.xml上記のように各グループでルールを定め、クローラーのアクセスを制御するのが特徴です。
user-agentの記述について
user-agentは、どの検索エンジンのクローラーに対してrobots.txtの記述を適用するかを指定する箇所です。
▼すべての検索エンジンのクローラーをブロック
User-agent: * ▼Googleのクローラーのみをブロック
User-agent: Googlebot▼GoogleとBingのクローラーのみをブロック
User-agent: Bingbot全文記載すると、以下のようになります。
# Googleのクローラーをブロック
User-agent: Googlebot
Disallow: /
# Bingのクローラーをブロック
User-agent: Bingbot
Disallow: /
# 上記以外のすべてのクローラーはブロックしない
# (何も記述しないか、Allowを明記)
User-agent: *
Allow: /▼各検索エンジンのbot名
| Google,Yahoo! | Googlebot | Bing | Bingbot |
|---|---|---|---|
| Yandex | YandexBot | Baidu | Baiduspider |
| DuckDuckGo | DuckDuckBot | Naver | Yetibot |
Disallowの記述について
Disallowは、どのディレクトリやページのクロールを禁止するかを指定する箇所です。
▼サイト全体へのクロールを禁止する場合
Disallow: /▼特定のディレクトリへのクロールを禁止する場合
Disallow: /private/▼特定のページへのクロールを禁止する場合
Disallow: /members/profile/setting.html動的なURLパラメータがあるページを禁止する場合は、ワイルドカード * を使うのが便利です。
Disallow: /search?*session_id=上記の記述により、session_id= という文字列を含む search ページのクロールを防ぐことができます。
▼特定のページへのクロールを禁止する場合(例:.pdfファイル)
Disallow: /*.pdf$Allowの記述について
Allowは、Disallowで大きな範囲を禁止しつつ、その中の一部だけクロールを許可したい場合に使用します。
Allowは、Disallowよりも後に記述します。
User-agent: *
Disallow: /private/
Allow: /private/public/Sitemapの記述について
サイトの構造をクローラーに効率的に伝えるため、XMLサイトマップ(sitemap.xml)のURLを記述します。
User-agent: *
Disallow: /private/
Allow: /private/public/
Sitemap: https://www.example.com/sitemap.xmlrobots.txtファイル内のどこにでも記述できますが、一般的にはファイルの末尾に記述することが多いです。
おさえておきたい記述のポイント・注意点
以下の点を抑えておきましょう。
- クローラーはファイルを上から順に読み込み、最初に一致したものから適用します。
- 大文字と小文字を区別されます。
- 行の先頭に # を付けるとその行はコメントとして無視されます。
サンプルコード
サイト全体のクロールを禁止
User-agent: *
Disallow: /※URL自体がインデックスされる可能性はあります。
ディレクトリとその内容のクロールを禁止
User-agent: *
Disallow: /calendar/
Disallow: /junk/
Disallow: /books/fiction/contemporary/※全体を禁止するには、ディレクトリ名後にスラッシュを付けます。
特定のファイル形式のクロールを禁止
User-agent: Googlebot
Disallow: /*.gif$
Disallow: /*.pdf$例: .gifや.pdfファイルのクロールを拒否
特定の1つのクローラーを除く全てのクローラーに対してアクセスを許可
User-agent: Unnecessarybot
Disallow: /
User-agent: *
Allow: /例: Unnecessarybotはサイトをクロールできず、それ以外のbotは全てできます。
これらのルールを組み合わせることで、サイト内の特定の部分へのクローラーのアクセスを細かく制御することができます。
3. robots.txt ファイルのアップロード
作成したrobots.txtファイルを、検索エンジンのクローラーがアクセスできるようにサイトに設置しましょう。
ファイルの設置方法は、サイトやサーバーの環境によって異なります。
具体的な手順については、ご利用のホスティング事業者に確認するか、事業者のドキュメントを参照してください。
アップロードする際の手順は以下の通りです。
- 配置場所:サイトのルートディレクトリに設置します。
(例:https://www.example.com/robots.txt) - ファイル名:ファイル名は「robots.txt」とします。
- アクセス可能性:アップロード後、ファイルが一般公開されており、Googleを含む検索エンジンのクローラーがアクセスできるか確認します。
アップロードが完了したら、ファイルが正しく設定されているかテストツールなどで確認するようにしましょう。
4. robots.txt のマークアップのテストする
robots.txtファイルを設定したら、その記述が正しく機能するかを確認することが重要です。
Googleでは、主に2つの方法でrobots.txtファイルのマークアップをテストできます。
①Google Search Consoleで確認する方法
サイトにアップロード済みのrobots.txtファイルにアクセスし、エラーや警告を確認できます。
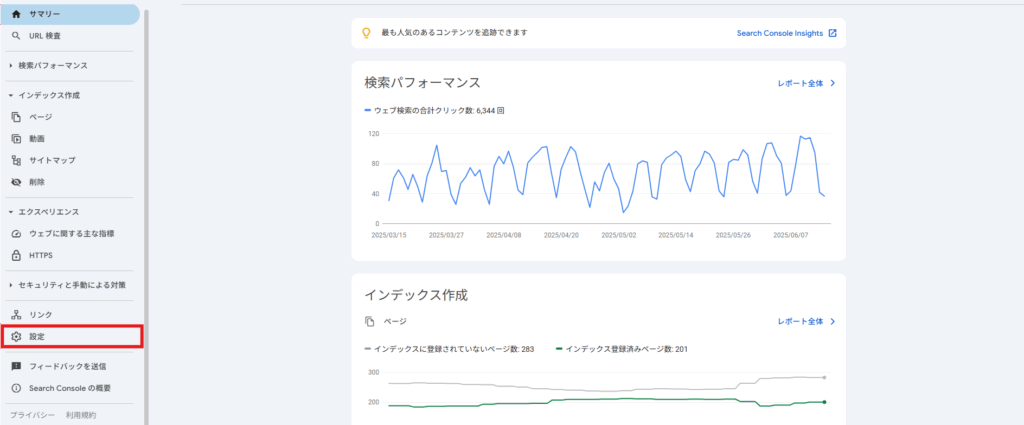
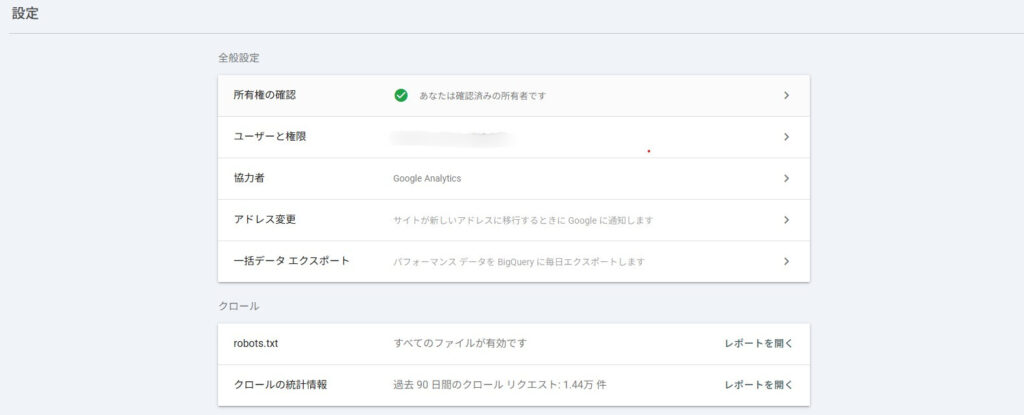
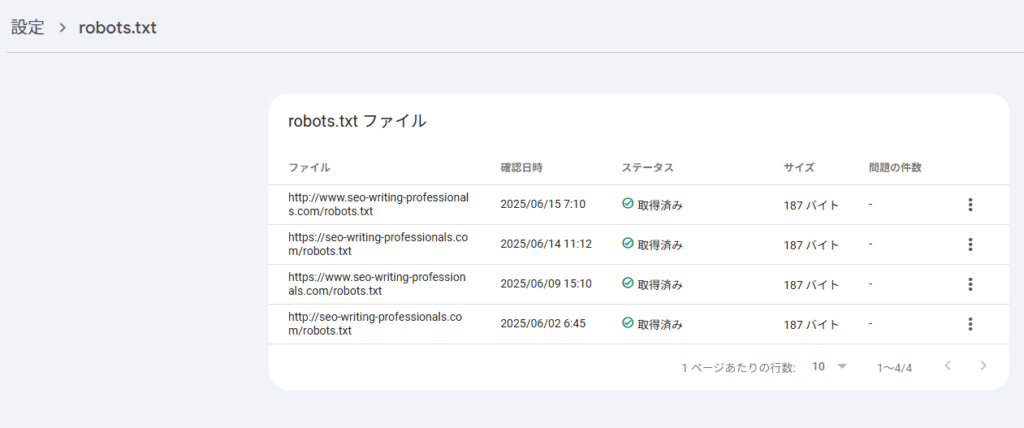
ステータスがエラーになっている場合は、記述方法やファイル形式に問題があるので、確認し再度作成してみましょう。
再アップロード後に、再クロールをこの画面からリクエストすることができます。
②Googleが公開しているオープンソースのrobots.txtライブラリを確認する方法
Googleが公開しているオープンソースのrobots.txtライブラリ(robotstxt-parser)を使用すると、Google Search Consoleのようなツールを使わずに、プログラム上で特定のURLが特定のクローラー(ユーザーエージェント)に対して許可されているかを確認できます。
ここでは、Pythonを使った確認方法を説明します。
まず、ターミナルまたはコマンドプロンプトで、pipを使用してライブラリをインストールします。
pip install google-robotstxt-parser以下は、特定のrobots.txtの内容に対して、URLがクロール可能かどうかを判定する基本的なコードの例です。
import robotstxt_parser
# --- 確認したいrobots.txtの内容を文字列として用意 ---
# 実際の使用では、requestsライブラリなどでサイトから直接取得することも可能です。
robots_txt_content = """
User-agent: *
Disallow: /private/
Disallow: /admin/
User-agent: Googlebot
Allow: /private/some-public-page.html
Disallow: /private/
User-agent: Bingbot
Disallow: /
"""
# --- パーサーの準備とrobots.txtの読み込み ---
# パーサーのインスタンスを作成
parser = robotstxt_parser.RobotstxtParser()
# robots.txtの内容をパース(解析)
parser.parse(robots_txt_content.splitlines())
# --- クロールの許可/不許可をチェック ---
# ケース1: Googlebotが特定のプライベートページにアクセスできるか?
# Allowルールが優先されるため、Trueになるはず
is_allowed_google = parser.is_allowed("Googlebot", "https://example.com/private/some-public-page.html")
print(f"Is Googlebot allowed for /private/some-public-page.html? -> {is_allowed_google}") # -> True
# ケース2: Googlebotが別のプライベートページにアクセスできるか?
# Disallowルールに合致するため、Falseになるはず
is_allowed_google_private = parser.is_allowed("Googlebot", "https://example.com/private/secret-file.html")
print(f"Is Googlebot allowed for /private/secret-file.html? -> {is_allowed_google_private}") # -> False
# ケース3: その他のクローラー(例:AhrefsBot)が公開ページにアクセスできるか?
# User-agent: * のルールが適用される
is_allowed_other = parser.is_allowed("AhrefsBot", "https://example.com/public/page.html")
print(f"Is AhrefsBot allowed for /public/page.html? -> {is_allowed_other}") # -> True
# ケース4: Bingbotがサイトのどのページにもアクセスできるか?
# Disallow: / はサイト全体をブロックするため、Falseになるはず
is_allowed_bing = parser.is_allowed("Bingbot", "https://example.com/any-page.html")
print(f"Is Bingbot allowed for /any-page.html? -> {is_allowed_bing}") # -> False動作確認を行い、必要に応じて修正することで、検索エンジンによるサイトの評価やパフォーマンス管理を最適化できます。
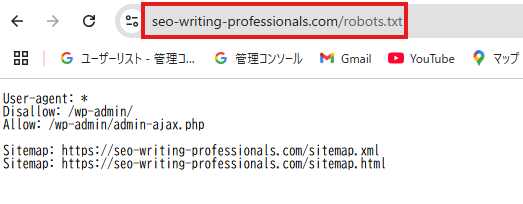
テスト前にrobots.txtファイルが一般公開されているかを確認してください。ブラウザで
「https://(あなたのサイト名).com/robots.txt」にアクセスして確認することができます。
以下のように表示されればOKです。
5. robots.txt ファイルの Google への送信
robots.txt ファイルは、サイトのルートディレクトリにアップロードして正しくテストが完了すれば、Google のクローラーが自動的に検出し、利用を開始します。
ただし、robots.txt ファイルの内容を更新した場合など、Google が保持しているrobots.txt のキャッシュを速やかに更新してほしい場合は、Google に送信するという手順を踏むことで、より早く変更を反映させることができます。
robots.txt ファイルの更新を Google に伝える方法
- Google Search Console にログインします。
- 該当するプロパティを選択します。
- 左メニューの「設定」をクリックします。
- 「クロール」セクションにある「robots.txt」の「レポートを開く」をクリックします。
- 右側から「再クロールをリクエスト」をクリックします。
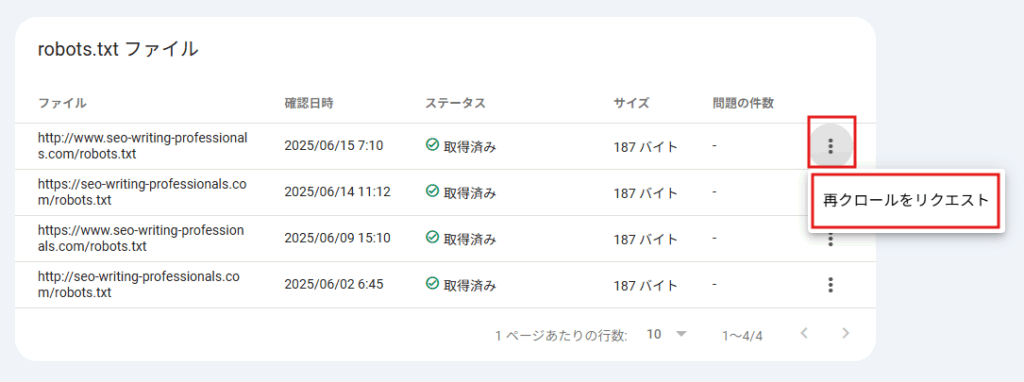
これにより、Google に最新の robots.txt ファイルの情報を伝えることができます。
robots.txtを活用する上での注意点は?
robots.txtを活用する際は、以下の点に注意が必要です。
- 反映までにタイムラグがある
- クロール拒否はアクセス制限ではない
- 重複コンテンツ対策としては不十分
- 小規模サイトでは過度な設定は不要
- 各サブドメインへ個別のrobots.txtの用意が必要
それぞれ見ていきましょう。
反映までにタイムラグがある
robots.txtの設定変更が検索エンジンに反映されるまで時間がかかる場合があります。
すぐに効果を期待しすぎないよう注意しましょう。
渡邉サイト公開時は特に、管理画面など絶対にクロールさせたくないページをクロールさせないためにも、robots.txtが問題なく設定できているようにしましょう。
クロール拒否はユーザーのアクセスを制限するわけではない
robots.txtでクロールを拒否しても、ユーザーが直接URLを入力した場合は通常通りアクセスできます。
機密情報など見られたくない内容はパスワード保護など別の方法で守るようにしましょう。
重複コンテンツ対策としては不十分
重複コンテンツの問題はrobots.txtだけでは解決できません。
noindexタグや正規化(canonical)設定も併用することが望ましいです。
重複コンテンツの対策方法について詳しくは下記の記事をご覧ください。

小規模サイトでは過度な設定は不要
数千ページ以下の規模であれば、robots.txtによるクロール最適化は必須ではありません。
むしろ、ノウハウの不足している状態でrobots.txtを使用すると、必要なページのインデックスを妨げてしまう場合もあるので、注意しましょう。
渡邉robots.txtは高度なSEOノウハウが求められるので、不安な場合は弊社のような専門会社にご相談ください。
各サブドメインへ個別のrobots.txtの用意が必要
運用している全てのサブドメインは、それぞれが独立したrobots.txtファイルを持つ必要があります。
例えば、cloudflare.com に専用のファイルがあるだけでなく、blog.cloudflare.com や community.cloudflare.com といった関連する全てのサブドメインにも、個別のrobots.txtファイルを用意しなくてはなりません。
なお、サブディレクトリ(example.com/blog/)には設定できません。
以上の注意点を把握したうえでrobots.txtを適切に運用し、サイトのパフォーマンス管理に役立ててください。
robot.txtファイルに関するやや高度な情報
ここまで、robot.txtファイルに関して、SEO担当者やWeb担当者として知っておきたい情報は一通り解説いたしました。
ここでは、中級者・上級者向けにやや高度な情報にも触れていきます。
robot.txtの仕組み
robots.txtとは、HTMLのようなマークアップコードを含まない、純粋なテキスト形式のファイルです。
そのため拡張子は「.txt」となります。robots.txt
ファイルは、ウェブサイトを構成する他のデータと同様にウェブサーバー上に配置されています。
実際に、どのウェブサイトのrobots.txtも、通常は対象ドメインのURLの末尾に「/robots.txt」を付け加えることで、誰でもその内容を閲覧することが可能です。
サイト内のどこからもリンクが設定されていないため、一般ユーザーがその存在に気づくことは稀ですが、以下のようにページが存在しています。(自社サイトURLの末尾に「/robots.txt」と入れてみましょう。)
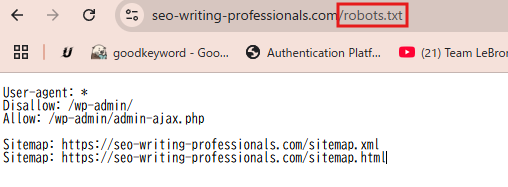
検索エンジンなどのクローラーは、サイト内の各ページを読み込む前に、まずこのファイルを参照しにきます。
robots.txtに強制力はない
robots.txtファイルはbotに対してウェブサイト内での動きに関するガイドラインをとなりますが、その指示に技術的な強制力はありません。
Googlebotをはじめ、検索エンジンのクローラーやニュースアグリゲーターのような行儀の良いbotは、ドメイン内の情報を収集する前にrobots.txtを確認し、そこに書かれたルールを遵守します。
その一方で、スクレイピング用のbotや悪意を持ったbotは、このファイルを完全に無視するか、逆にアクセスを禁止されている箇所を特定する手がかりとして悪用することもあります。
悪意のあるbotへの対策は、サーバー側でのアクセス制限や専門的なセキュリティツールの導入が必要です。
robots.txtファイル内に矛盾する指令があった場合
クローラーは、robots.txt内に記述された命令の中で、最も限定的で詳細なものを優先して解釈します。
もしファイル内に互いに矛盾するような指令が存在した場合、botはより具体的なルールの方に従う設計になっています。
robots.txtファイルで使用されているプロトコルファイル
robots.txtファイルは、ウェブサイトとクローラーとの間のコミュニケーションを制御するためのファイルです。
このファイルは、主に以下の2つのプロトコルに基づいています。
| プロトコル | 説明 |
|---|---|
| Robots Exclusion Standard (ロボット排除標準) | クローラーに対して、サイト内のどのURLへのアクセスを許可または禁止するかを指示するためのプロトコルです。robots.txtファイルに記述されるUser-agent、Disallow、Allowなどのディレクティブは、この標準に基づいています。これは、クローラーに「ここには来ないでください」と伝える役割を果たします。 |
| Sitemaps protocol (サイトマッププロトコル) | robots.txtファイル内でSitemapディレクティブを使用して、サイトマップファイルの場所をクローラーに知らせるために使用されます。サイトマップは、サイト内の重要なページのリストであり、クローラーが効率的にサイトをクロールし、新しいコンテンツや更新されたコンテンツを発見するのを助けます。これは、クローラーに「これらのページはクロールできますよ」と伝える役割を果たします。 |
このように、robots.txtファイルは、主にロボット排除標準を用いてアクセスの制御を行い、サイトマッププロトコルを用いてサイト構造の情報を提供します。
robots.txtと合わせて知っておきたいmeta robotsによる各種設定
robots.txtと、関連性の高い設定項目として、meta robotsによるnoindexやnofollowの設定方法についても理解しておきましょう。
noindexやnofollowは、以下のようにmeta robotsで<head> セクション内に記述されます。
<meta name=”robots” content=”noindex,nofollow”>
上記の例では、ページをインデックス登録せず、リンクもたどられないように設定しています。
meta robotsはrobots.txtファイルとは異なり、ページ単位で細かい制御が可能なため、用途に応じて使い分けることが重要です。
meta robotsを利用すると、各ページごとに検索エンジンへのクロールやインデックスの制御が可能です。代表的な指定例は以下のとおりです。
| 指定内容 | 意味 |
|---|---|
| index | ページを検索エンジンのデータベースに登録することを許可します。 |
| noindex | ページを検索エンジンのデータベースに登録しないよう指示します。 |
| follow | ページ内のリンクを検索エンジンがたどることを許可します。 |
| nofollow | ページ内のリンクを検索エンジンがたどらないよう指示します。 |
まとめ
robots.txtファイルは、検索エンジンのクローラーに対してサイト内のクロール許可や禁止の指示を出す重要なファイルです。
適切に設定することで、不要なページのクロールを防ぎ、SEO効果の向上につながります。
robots.txtを活用してSEO対策を強化していきましょう!
- 狙ったキーワードで検索上位がとれていない
- 戦略的にSEO対策をしたい
- 検索順位改善だけでなく売上・利益にもつなげたい
現在、上記のようなお困りごとがありましたら、SEOコンサルティングで圧倒的な成果を創出してきた我々『シュワット株式会社』へご相談ください。SEO対策にとどまらず売上・利益などビジネス的な成果を追求し、戦略設計から施策の実行、インハウス化支援まで、ニーズに合わせた最適なプランで強力にサポートいたします。







